RenderBlock
链接:https://juejin.cn/post/7062552765117136903
https://developer.android.com/topic/performance/rendering/profile-gpu?hl=zh-cn
RenderThread的作用:
主线程的 draw 函数并没有真正的执行 drawCall ,而是把要 draw 的内容记录到 DIsplayList 里面(在 Measure、Layout、Draw 的 Draw 这个环节,Android 使用 DisplayList 进行绘制而非直接使用 CPU 绘制每一帧。),同步到 RenderThread 中,一旦同步完成,主线程就可以被释放出来做其他的事情,RenderThread 则继续进行渲染工作
2.3 生产者和消费者
我们再回到 Vsync 的话题,消费 Vsync 的双方分别是 App 和 sf,其中 App 代表的是生产者,sf 代表的是消费者,两者交付的中间产物则是 surface buffer。
再具体一点,生产者大致可以分为两类,一类是以 window 为代表的页面,也就是我们平时所看到的 view 树这一套;另一类是以视频流为代表的可以直接和 surface 完成数据交换的来源,比如相机预览等。
对于一般的生产者和消费者模式,我们知道会存在相互阻塞的问题。比如生产者速度快但是消费者速度慢,亦或是生产者速度慢消费者速度快,都会导致整体速度慢且造成资源浪费。所以 Vsync 的协同以及双缓冲甚至三缓冲的作用就体现出来了。
思考一个问题:是否缓冲的个数越多越好?过多的缓冲会造成什么问题?
答案是会造成另一个严重的问题:lag,响应延迟
这里结合 view 的一生,我们可以把两个流程合在一起,让我们的视角再高一层:
我们一般都比较了解 view 渲染的三大流程,但是 view 的渲染远不止于此:
此处以一个通用的硬件加速流程来表征
- Vsync 调度:很多同学的一个认知误区在于认为 vsync 是每 16ms 都会有的,但是其实 vsync 是需要调度的,没有调度就不会有回调;
- 消息调度:主要是 doframe 的消息调度,如果消息被阻塞,会直接造成卡顿;
- input 处理:触摸事件的处理;
- 动画处理:animator 动画执行和渲染;
- view 处理:主要是 view 相关的遍历和三大流程;
- measure、layout、draw:view 三大流程的执行;
- DisplayList 更新:view 硬件加速后的 draw op;
- OpenGL 指令转换:绘制指令转换为 OpenGL 指令;
- 指令 buffer 交换:OpenGL 的指令交换到 GPU 内部执行;
- GPU 处理:GPU 对数据的处理过程;
- layer 合成:surface buffer 合成屏幕显示 buffer 的流程;
- 光栅化:将矢量图转换为位图;
- Display:显示控制;
- buffer 切换:切换屏幕显示的帧 buffer;
2.4 机制上的保护
这里我们来回答第三个问题,从系统的渲染架构上来说,机制上的保护主要有几方面:
Vsync 机制的协同;
多缓冲设计;
surface 的提供;
同步屏障的保护;
硬件绘制的支持;
渲染线程的支持;
GPU 合成加速;
2.5 再看卡顿的成因
渲染流程
Vsync 调度:这个是起始点,但是调度的过程会经过线程切换以及一些委派的逻辑,有可能造成卡顿,但是一般可能性比较小,我们也基本无法介入;
消息调度:主要是 doframe Message 的调度,这就是一个普通的 Handler 调度,如果这个调度被其他的 Message 阻塞产生了时延,会直接导致后续的所有流程不会被触发。这里直播建立了一个 FWtachDog 机制,可以通过优化消息调度达到插帧的效果,使得界面更加流畅;
input 处理:input 是一次 Vsync 调度最先执行的逻辑,主要处理 input 事件。如果有大量的事件堆积或者在事件分发逻辑中加入大量耗时业务逻辑,会造成当前帧的时长被拉大,造成卡顿。抖音基础技术同学也有尝试过事件采样的方案,减少 event 的处理,取得了不错的效果;
动画处理:主要是 animator 动画的更新,同理,动画数量过多,或者动画的更新中有比较耗时的逻辑,也会造成当前帧的渲染卡顿。对动画的降帧和降复杂度其实解决的就是这个问题;
view 处理:主要是接下来的三大流程,过度绘制、频繁刷新、复杂的视图效果都是此处造成卡顿的主要原因。比如我们平时所说的降低页面层级,主要解决的就是这个问题;
measure/layout/draw:view 渲染的三大流程,因为涉及到遍历和高频执行,所以这里涉及到的耗时问题均会被放大,比如我们会降不能在 draw 里面调用耗时函数,不能 new 对象等等;
//以下对应的是**淡蓝色、红色、橘色**色块对应的阶段
DisplayList 的更新:这里主要是 canvas 和 displaylist 的映射,一般不会存在卡顿问题,反而可能存在映射失败导致的显示问题;
OpenGL 指令转换:这里主要是将 canvas 的命令转换为 OpenGL 的指令,一般不存在问题。不过这里倒是有一个可以探索的点,会不会存在一类特殊的 canvas 指令,转换后的 OpenGL 指令消耗比较大,进而导致 GPU 的损耗?有了解的同学可以探讨一下;
指令buffer 交换:这里主要指 OpenGL 指令集交换给 GPU,这个一般和指令的复杂度有关。一个有意思的事儿是这里一度被我们作为线上采集 GPU 指标的数据源,但是由于多缓冲的因素数据准确度不够被放弃了;
GPU 处理:顾名思义,这里是 GPU 对数据的处理,耗时主要和任务量和纹理复杂度有关。这也就是我们降低 GPU 负载有助于降低卡顿的原因;
layer 合成:这里主要是 layer 的 compose 的工作,一般接触不到。偶尔发现 sf 的 vsync 信号被 delay 的情况,造成 buffer 供应不及时,暂时还不清楚原因;
光栅化:这里暂时忽略,底层系统行为;
Display:这里暂时忽略,底层系统行为;
Buffer 切换:主要是屏幕的显示,这里 buffer 的数量也会影响帧的整体延迟,不过是系统行为,不能干预。
Google 将这个过程划分为:其他时间/VSync 延迟、输入处理、动画、测量/布局、绘制、同步和上传、命令问题、交换缓冲区。也就是我们常用的 GPU 严格模式,其实道理是一样的。到这里,我们也就回答出来了第二个问题:16ms 内都需要完成什么?
准确地说,这里仍可以进一步细化:16ms 内完成 APP 侧数据的生产;16ms 内完成 sf layer 的合成
View 的视觉效果正是通过这一整条复杂的链路一步步展示出来的,有了这个前提,那就可以得出一个结论:上述任意链路发生卡顿,均会造成卡顿。
补充硬件绘制
DisplayList更新详解
硬件绘制还引入了一个 DisplayList 的概念,
DisplayList
每个 View 内部都有一个DisplayList,当某个 View 需要重绘时,将它标记为 Dirty。当需要重绘时,仅仅只需要重绘一个 View 的 DisplayList,而不是像软件绘制那样需要向上递归。这样可以大大减少绘图的操作数量,因而提高了渲染效率
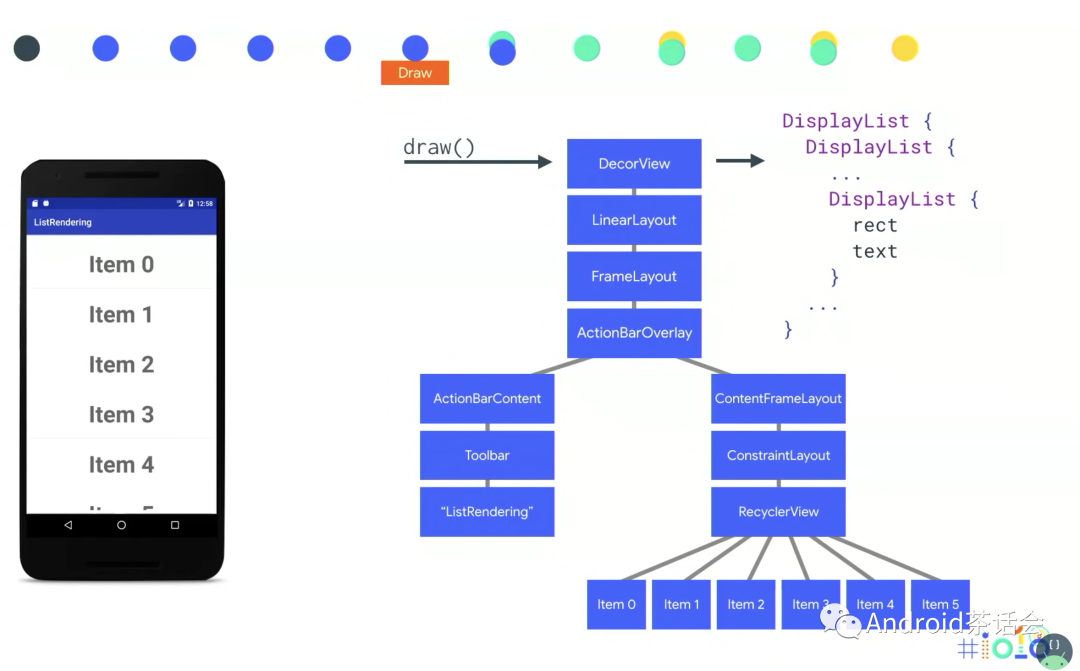
Display List 是一个缓存绘制命令的 Buffer,Display List 的本质是一个缓冲区,它里面记录了即将要执行的绘制命令序列。Display List 是视图的基本绘制元素,包含元素原始属性(位置、尺寸、角度、透明度等),对应 Canvas 的 drawXxx()方法。类似于左边图中所示一样,onDraw会被DisplayList所表示。ViewTree中每一个View都会有对应的DisplayList来代表。
本例子中,点击Item2,触发onDraw之后,DisplayList开启了如下的操作:
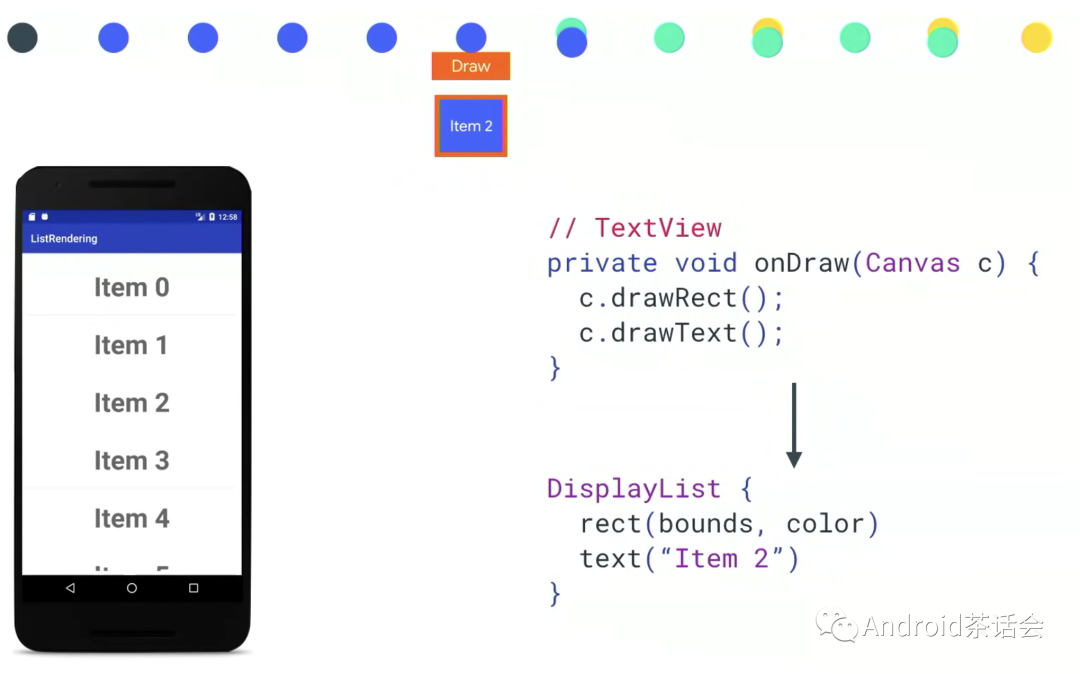
Sync
在Java层(UI Thread),我们收集组合所有信息,然后把这些信息sync给Native层,由RenderThread用GPU渲染。
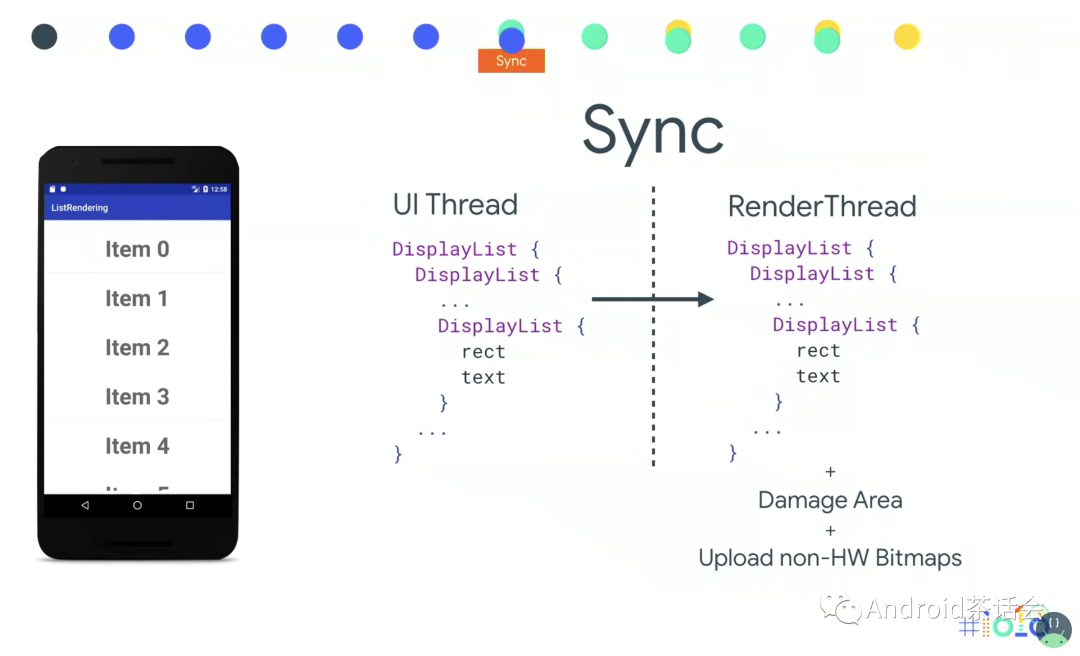
Damage Area: 这个概念类似于Dirty Region,意思是需要被重新绘制的区域,在我们这个例子中就是item2的区域。
Upload non-HW Bitmaps: 把non-HW Bitmaps上传到GPU的RAM里,此时一帧刚刚开始,有比较充足的时间。相反的是,
对Hardward Bitmap没有这步操作,Hardward Bitmap是一种新的位图配置,是在Android Oh中添加的 通常当你有一个位图时我们必须在Java端分配内存,然后在需要绘制的时候 我们必须在GPU上复制位图,这在文本时间上是昂贵的,它使我们的RAM数量增加了一倍。使用Oreo中可用的硬件位图,它已经存在GPU一侧了 如果你不打算修改这个位图,从内存角度来看确实是一个非常有效的存储位图的方式。
RenderThread
Android 5.0 (Lollipop)引入的,此线程只在Native层跟GPU交互,在Java层没有任何调用。渲染之前,我们生成DisplayList,然后我们把这些信息sync给GPU。它是串行执行的,但是RenderThread在这之中能够以原子操作(Atomic Operations)形式执行 例如波纹动画动画,矢量动画等。这些渲染转移到RenderThread来分担之后, UI Thread就可以在idle的时候做些别的事,比如RecyclerView的prefech机制就是设计在此时发生。
**DLOps **
(Display List Operations)
在GPU得到 Display List 后,DL 会转换成 DLOps。注意这个变成绿色的Fill操作,经过一系列**优化重排序(Optimization, Reordering and Batching)**后,它的位置被提到上面跟其他的Fill放在一起。优化(Optimization)包括将View setAlpha(),setHarewareLayer()这些操作的指令移到最前面执行,避免在GPU内进行昂贵的State变更操作。
重排序(Reordering)意思是当存在一系列的drawText(), drawRect()之类指令穿插存在时,相同的指令会被放在相邻的顺序执行。
而Batching表示一个drawText call就可以把整个屏幕上的需要drawText的地方全部做完。
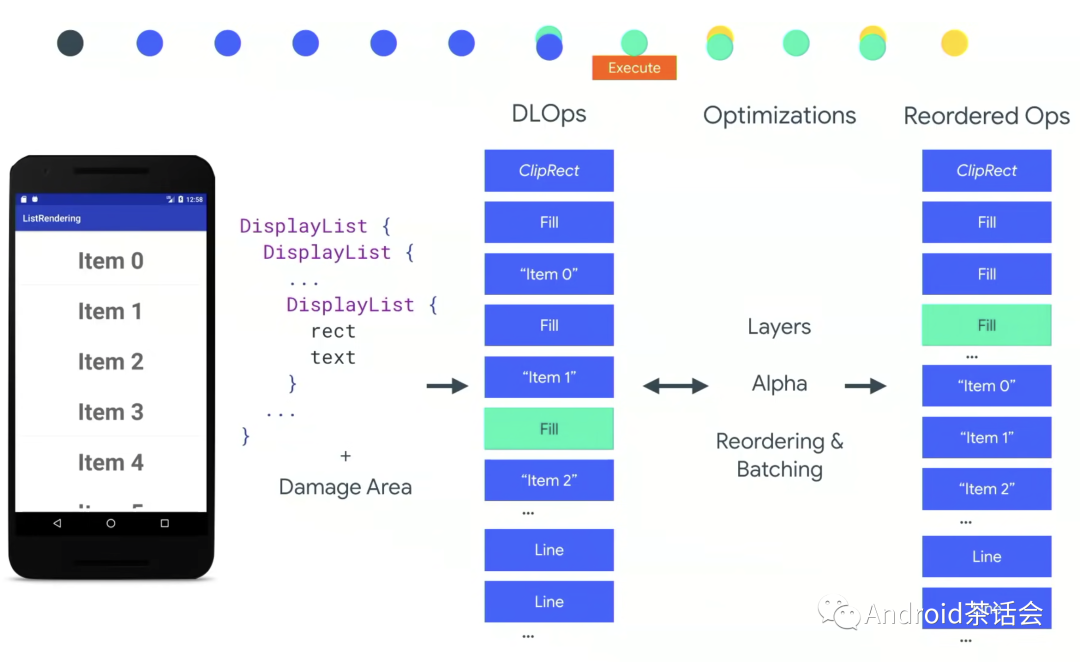
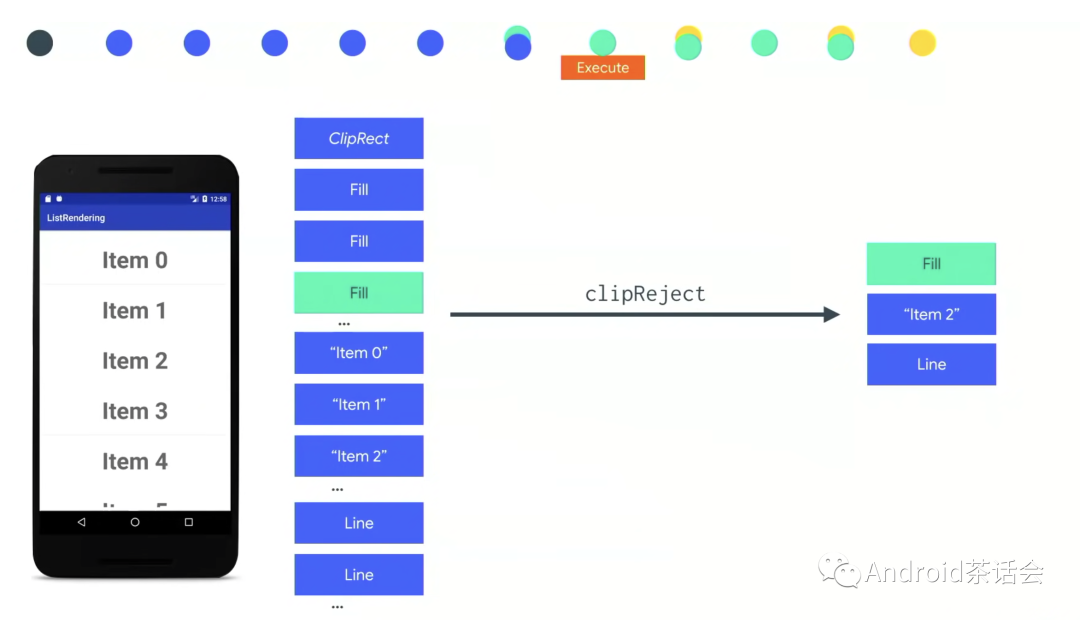
Clip Reject
在 Clip Reject中,我们判断哪些操作是必须的,换句话说哪些操作是相关脏区(Damaged Area)的。例如下图中,只有右边的三个操作是跟把item2背景变绿这个效果相关的。所以我们只需要执行右边三个DLOps。
接下来我们需要拿到缓冲区,虽然这里写的是Get Buffer,但实际情况是buffer不是申请来的,有关GPU的操作一执行,SurfaceFlinger就会分配Buffer过来,让我们执行这些操作。
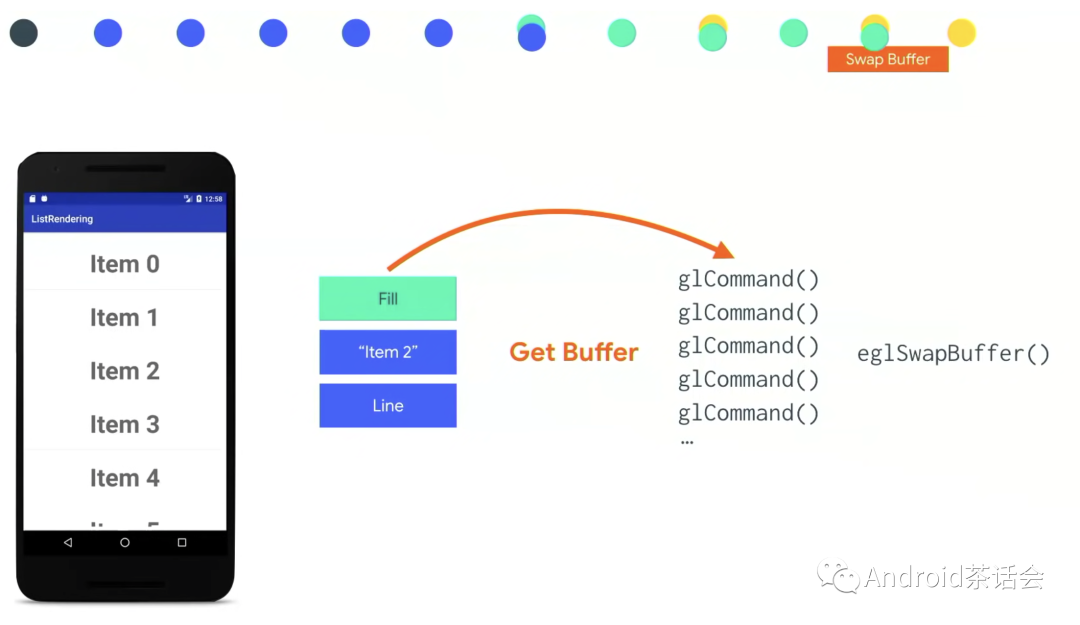
然后我们发出一系列GL指令来做画背景,画线,复制bitmap之类的实际操作。当这些操作全部结束时,我们会通知SurfaceFlinger去swap buffer。这时这一帧就完成了,它将被显示在屏幕上。同时,在 SurfaceFlinger 和 HardwareCompositor 中会进行Surface合成。Status Bar,System Bar 和 Content在这里会合成在一起,然后展示在屏幕上。
补充Composition
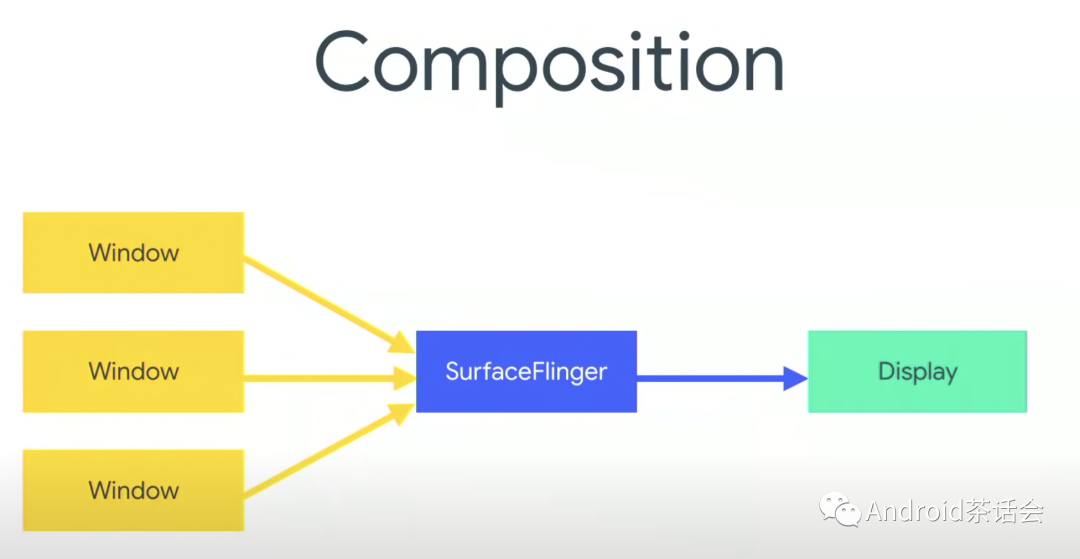
在上面的两个例子中,都略过了composition这一步具体里面发生了什么。在这节我们会进行进一步解释,SurfaceFlinger和HardwareCompositor是怎么把不同的window合成,然后展示到屏幕上的。在我们开始前,我们需要先搞清楚下面这三个概念:BufferQueue, Producer, Consumer。
BufferQueue
BufferQueue就是有若干个Buffer的Queue。Graphic Buffer存在在这里。一般会有1~3个Buffer,取决于setBufferQueue时的配置。
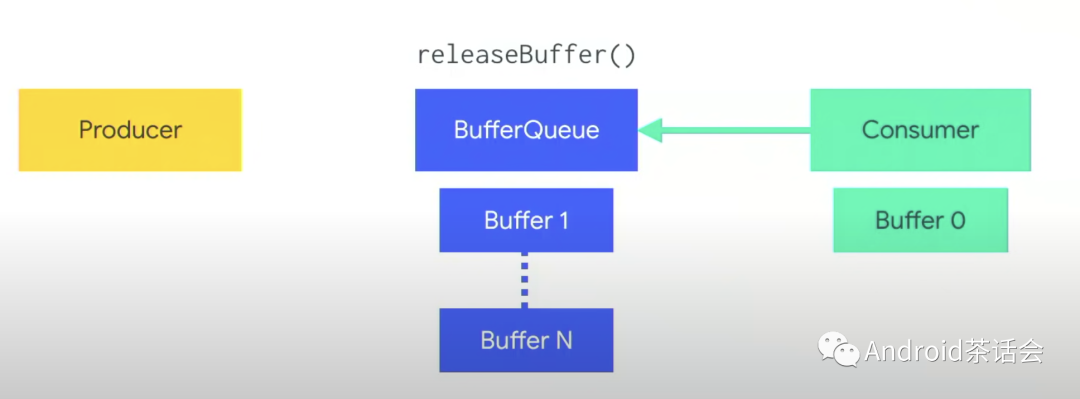
Producer
- 就和其他所有生产消费者模型一样,它负责生产内容,具体一点,在这里它生产要被展示在屏幕上的数据。
- 调用dequeBuffer()来从BufferQueue获得队首Buffer。这时它可以直接在Buffer写入Pixel数据,或调用OpenGL,或者使用Canvas。
- 当内容生产完之后,调用queueBuffer()将这个Buffer还给BufferQueue,放到队尾。
Comsumer
- 消费者要消费数据来展示到屏幕上。
- 调用acquireBuffer()拿到BufferQueue中第一个可用的(一般在队尾)Buffer,读取里面的数据。
- 内容消费完成后,调用releaseBuffer()给放回队首。
Create Window
当我们创建一个Window时,例如activity,dialog,popup window等。在Producer侧,WindowManager会在内部创建个Window对象(这里会创建ViewRootImp来关联view的操作,surface也是跟window一一绑定)。而在Consumer侧,SurfaceFlinger会管理各个Surface相对应的生成一个Layer对象(layer的东西也太多了)。Layer是系统组件之一,它创建和管理BufferQueue。之后在App中会生成一个Surface对象。
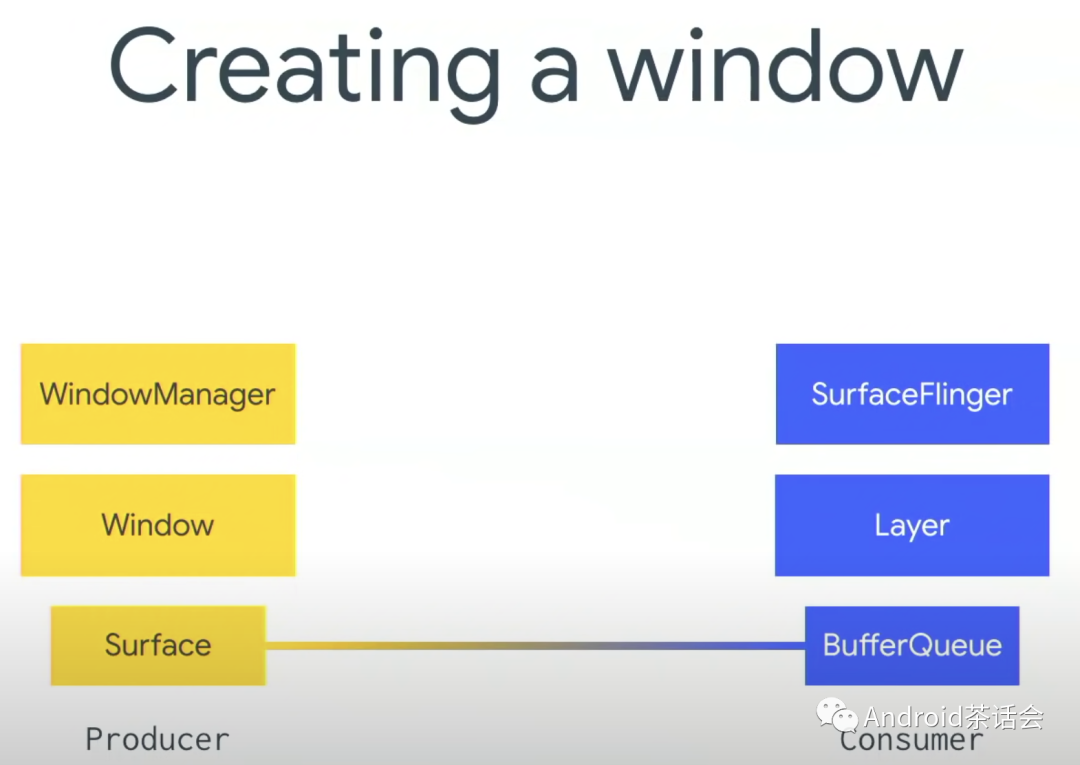
Surface
- Surface 对应了一块屏幕缓冲区,每个 Window 对应一个 Surface,任何 View 都是画在 Surface 上的,传统的 View 共享一块屏幕缓冲区。
- 所有的绘制必须在 UI 线程中进行。
- 我们不能直接操作 Surface 实例,要通过 SurfaceHolder,在 SurfaceView 中可以通过 getHolder() 方法获取到 SurfaceHolder 实例。
SurfaceView
简单的说 SurfaceView 就是一个有 Surface 的 View,SurfaceView 控制这个 Surface 的格式和尺寸以及绘制位置。SurfaceView的实现原理相当于在Window的Surface打个洞,漏出SurfaceView的Surface。他们两个的Surface是完全相互独立的存在。
Surface Texture
Consumer是OpenGL。SurfaceTexture 会创建 BufferQueue 和 Surface。
TextureView
- 创建SurfaceTexture。
- RenderThread是Consumer,Producer可以自己选择。
- 就像个功能更强大的ImageView一样,更新得更快速。
在Android O或N之前的版本上,TexutreView是比SurfaceView更推荐使用的,因为一方面可以享受更快速的渲染,另一方面可以避免SurfaceView的种种问题,比如两个Window造成的效率折损,渲染不同步导致画面割裂等。但是这些问题已经都被解决了,在18年谷歌I/O大会上更推荐在新版本的安卓上使用SurfaceView,而不是TextureView。
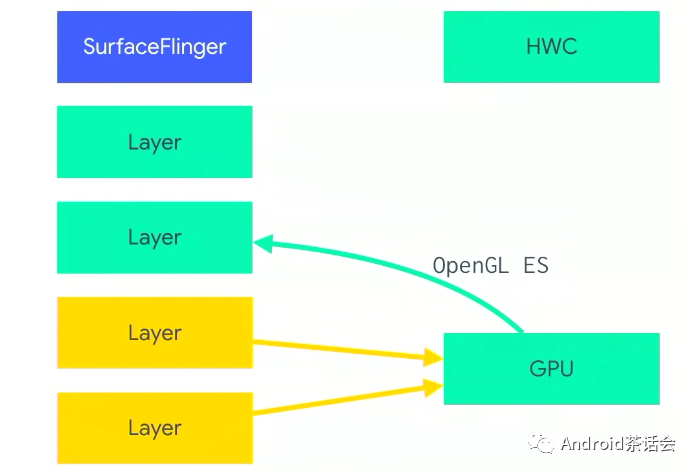
回到我们本节的主题Composition上。我们在应用中创建很多window,每个都有自己的layer,SurfaceFlinger来收集这些layer,SurfaceFlinger其实不是直接跟Display显示器交互,而是跟Hardware Composer沟通(HWC),它是一个硬件抽象层,我们通常为了省电,避免GPU直接在屏幕上合成显示。
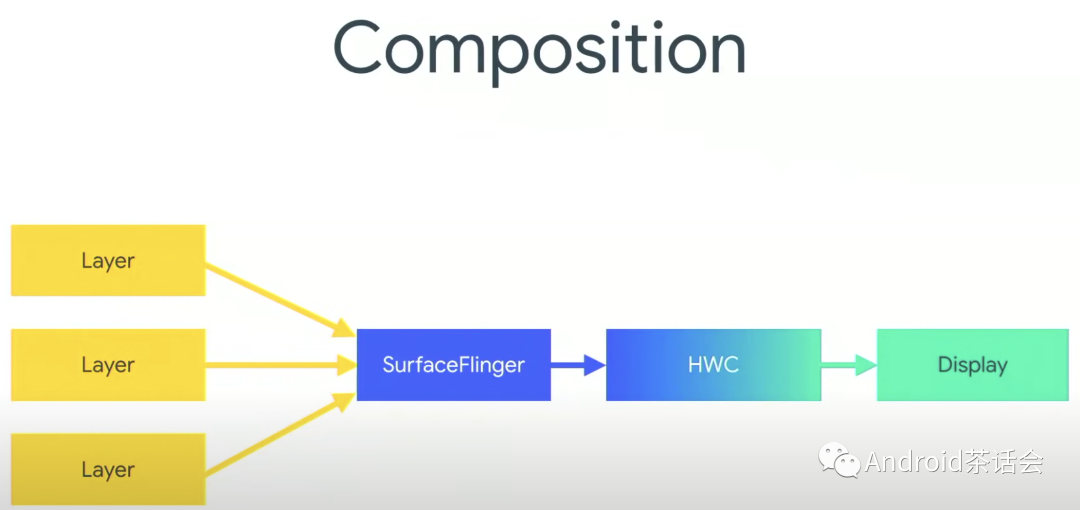
Hardware Composer HAL
是一个硬件抽象层用于确定通过可用硬件来合成缓冲区的最有效方法。
作为 HAL,其实现是特定于设备的,而且通常由显示硬件原始设备制造商 (OEM) 完成。
当您考虑使用叠加平面时,很容易发现这种方法的好处,它会在显示硬件(而不是 GPU)中合成多个缓冲区。例如,假设有一部普通 Android 手机,其屏幕方向为纵向,状态栏在顶部,导航栏在底部,其他区域显示应用内容。每个层的内容都在单独的缓冲区中。您可以使用以下任一方法处理合成:
- 将应用内容渲染到暂存缓冲区中,然后在其上渲染状态栏,再在其上渲染导航栏,最后将暂存缓冲区传送到显示硬件。
- 将三个缓冲区全部传送到显示硬件,并指示它从不同的缓冲区读取屏幕不同部分的数据。
后一种方法可以显著提高效率。显示处理器性能差异很大。叠加层的数量(无论层是否可以旋转或混合)以及对定位和重叠的限制很难通过 API 表达。为了适应这些选项,HWC 会执行以下计算:
- SurfaceFlinger 向 HWC 提供一个完整的Layer列表,并询问“您希望如何处理这些层?”
- HWC 的响应方式是将每个层标记为FrameBuffer或OVERLAY。
- SurfaceFlinger 会处理(计算的当前显示设备的脏区域DirtyRegion等工作)所有OVERLAY,将输出buffer传送到 HWC,并让 HWC 处理其余部分。
举个例子:SurfaceFlinger告诉HWC现在有3个Layer你想怎么办。HWC一看,第一个简单,OVERLAY就可以,第二个第三个我处理不了,需要GPU先处理下才行,就标记成FrameBuffer。
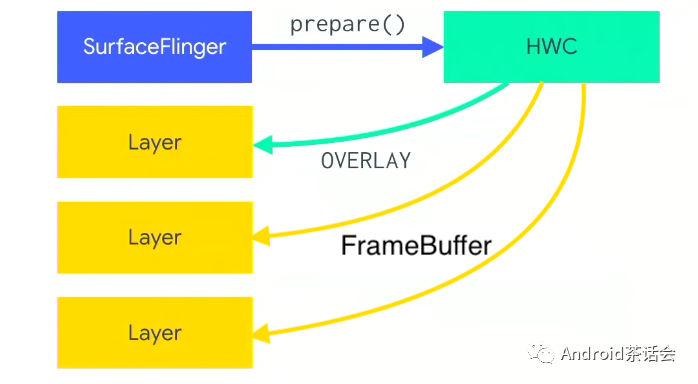
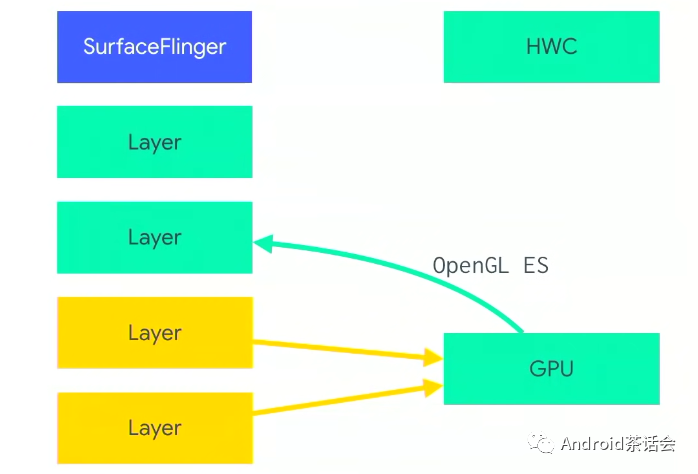
标记成FrameBuffer的这两层会被先行处理,处理这两层时,需要再添加一层来放output,被绿箭头指着的这层就是output,叫做Scratch Layer(叫什么名不重要,后面不会出现,只是为了避免混淆)。
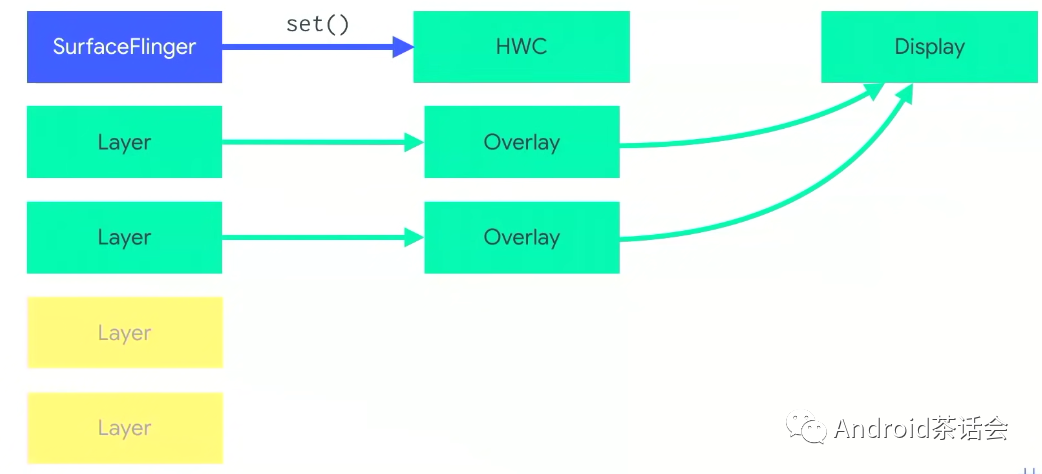
现在,剩下这两层Layer会被SurfaceFlinger用set()传到HWC,之后被渲染到屏幕上。感兴趣的大家可以用这个命令打印出SurfaceFlinger的大量信息。
1 | adb shell dumpsys SurfaceFlinger |
到这里,整个渲染的流程就已经串联完了。我们应用的 UI 是如何变成屏幕上的像素的,相信大家看到这里已经有了一个基本的概念。了解这些的工作原理可以帮助我们弄清楚如何为App获得最佳性能。
RenderBlock