privatevoidrunGenerators(){ currentThread = Thread.currentThread(); startFetchTime = LogTime.getLogTime(); boolean isStarted = false; while (!isCancelled && currentGenerator != null && !(isStarted = currentGenerator.startNext())) { stage = getNextStage(stage); currentGenerator = getNextGenerator(); if (stage == Stage.SOURCE) { reschedule(); return; } } // We've run out of stages and generators, give up. if ((stage == Stage.FINISHED || isCancelled) && !isStarted) { notifyFailed(); } // Otherwise a generator started a new load and we expect to be called back in // onDataFetcherReady. } private Stage getNextStage(Stage current){ switch (current) { case INITIALIZE: return diskCacheStrategy.decodeCachedResource() ? Stage.RESOURCE_CACHE : getNextStage(Stage.RESOURCE_CACHE); case RESOURCE_CACHE: return diskCacheStrategy.decodeCachedData() ? Stage.DATA_CACHE : getNextStage(Stage.DATA_CACHE); case DATA_CACHE: // Skip loading from source if the user opted to only retrieve the resource from cache. return onlyRetrieveFromCache ? Stage.FINISHED : Stage.SOURCE; case SOURCE: case FINISHED: return Stage.FINISHED; default: thrownew IllegalArgumentException("Unrecognized stage: " + current); } } private DataFetcherGenerator getNextGenerator(){ switch (stage) { case RESOURCE_CACHE: returnnew ResourceCacheGenerator(decodeHelper, this); case DATA_CACHE: returnnew DataCacheGenerator(decodeHelper, this); case SOURCE: returnnew SourceGenerator(decodeHelper, this); case FINISHED: returnnull; default: thrownew IllegalStateException("Unrecognized stage: " + stage); } }
磁盘缓存的存储顺序记录在journal文件中,有时该文件过大会导致glide初始过慢。(初始化磁盘缓存时需要提前加载journal文件,较长时间使用的情况改文件可能达到1m甚至更大,会导致一定的耗时。即使在异步线程中初始化,图片库后续的加载也需要等到journal文件加载完成才能进行后续操作。for write journal when read or write cache)
Engine.java { @Nullable private EngineResource<?> loadFromMemory( EngineKey key, boolean isMemoryCacheable, long startTime) { if (!isMemoryCacheable) { returnnull; }
//该缓存key存在于activiteResource,是弱引用存在于内存中的 EngineResource<?> active = loadFromActiveResources(key); if (active != null) { if (VERBOSE_IS_LOGGABLE) { logWithTimeAndKey("Loaded resource from active resources", startTime, key); } return active; }
//该缓存存在于cache EngineResource<?> cached = loadFromCache(key); if (cached != null) { if (VERBOSE_IS_LOGGABLE) { logWithTimeAndKey("Loaded resource from cache", startTime, key); } return cached; } returnnull; }
//如果该缓存key存在于activiteResource,对应的对象引用加1 @Nullable private EngineResource<?> loadFromActiveResources(Key key) { EngineResource<?> active = activeResources.get(key); if (active != null) { active.acquire(); }
final EngineResource<?> result; if (cached == null) { result = null; } elseif (cached instanceof EngineResource) { //一般情况都是从缓存cache中直接返回 // Save an object allocation if we've cached an EngineResource (the typical case). result = (EngineResource<?>) cached; } else { //兜底 result = new EngineResource<>( cached, /*isMemoryCacheable=*/true, /*isRecyclable=*/true, key, /*listener=*/this); } return result; } }
java.lang.IllegalArgumentException: View=android.widget.PopupWindow$PopupDecorView{2a10009 V.E...... R.....I. 0,0-0,0} not attached to window manager at android.view.WindowManagerGlobal.findViewLocked(WindowManagerGlobal.java:544) at android.view.WindowManagerGlobal.updateViewLayout(WindowManagerGlobal.java:433) at android.view.WindowManagerImpl.updateViewLayout(WindowManagerImpl.java:162) at android.widget.PopupWindow.update(PopupWindow.java:2226) at android.widget.PopupWindow.update(PopupWindow.java:2347) at android.widget.PopupWindow.alignToAnchor(PopupWindow.java:2517) at android.widget.PopupWindow.-$$Nest$malignToAnchor(Unknown Source:0) at android.widget.PopupWindow$1.onViewAttachedToWindow(PopupWindow.java:243) at android.view.View.dispatchAttachedToWindow(View.java:21423) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3502) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewGroup.dispatchAttachedToWindow(ViewGroup.java:3509) at android.view.ViewRootImpl.performTraversals(ViewRootImpl.java:3011) at android.view.ViewRootImpl.doTraversal(ViewRootImpl.java:2518) at android.view.ViewRootImpl$TraversalRunnable.run(ViewRootImpl.java:9389) at android.view.Choreographer$CallbackRecord.run(Choreographer.java:1451) at android.view.Choreographer$CallbackRecord.run(Choreographer.java:1459) at android.view.Choreographer.doCallbacks(Choreographer.java:1089) at android.view.Choreographer.doFrame(Choreographer.java:1003) at android.view.Choreographer$FrameDisplayEventReceiver.run(Choreographer.java:1431) at android.os.Handler.handleCallback(Handler.java:942) at android.os.Handler.dispatchMessage(Handler.java:99) at android.os.Looper.loopOnce(Looper.java:210) at android.os.Looper.loop(Looper.java:299) at android.app.ActivityThread.main(ActivityThread.java:8261) at java.lang.reflect.Method.invoke(Native Method) at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:559) at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:954)




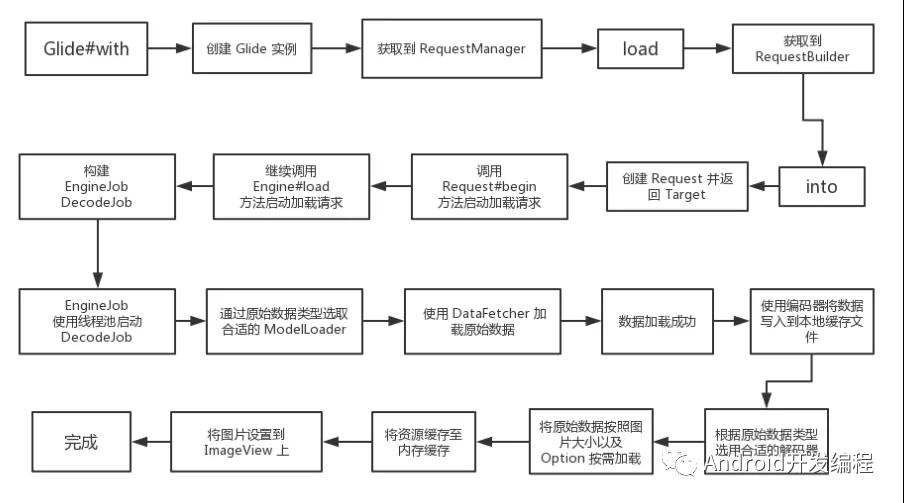
 这一串调用之后,走到遍历 decodePaths 尝试解析的步骤,此时一般有(AnimatedImageDecoder, ByteBufferGifDecoder, BitmapDrawableDecoder以及自定义的比如AvifBufferBitmapDecoder),任何一个decoder解码成功后即结束这段逻辑(decode时会执行Downsampler类的逻辑进行采样缩放并且解码),
这一串调用之后,走到遍历 decodePaths 尝试解析的步骤,此时一般有(AnimatedImageDecoder, ByteBufferGifDecoder, BitmapDrawableDecoder以及自定义的比如AvifBufferBitmapDecoder),任何一个decoder解码成功后即结束这段逻辑(decode时会执行Downsampler类的逻辑进行采样缩放并且解码),






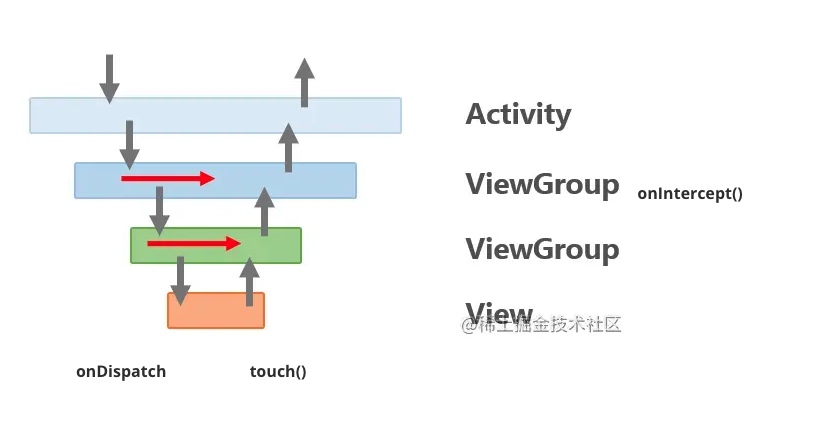


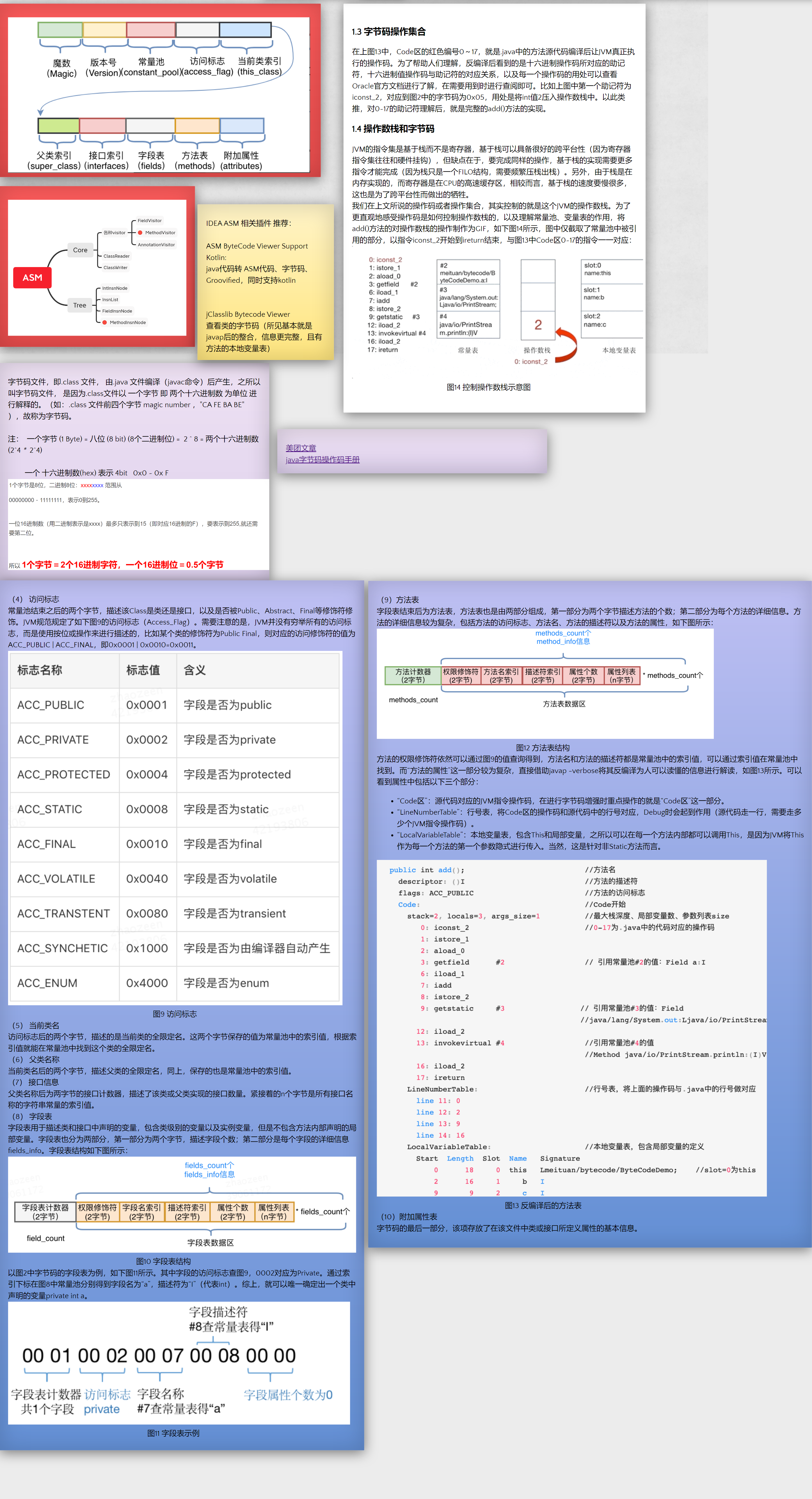
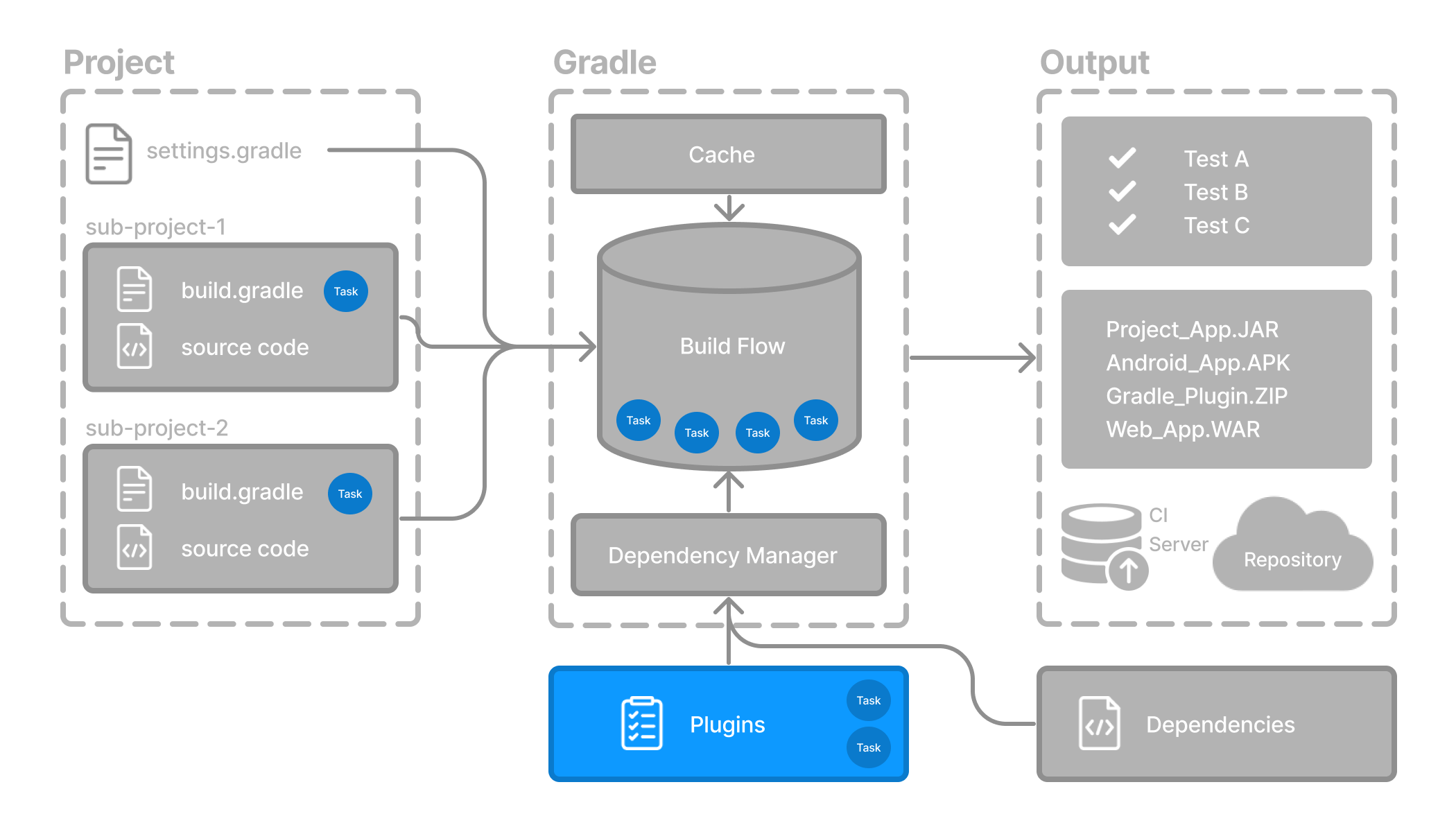
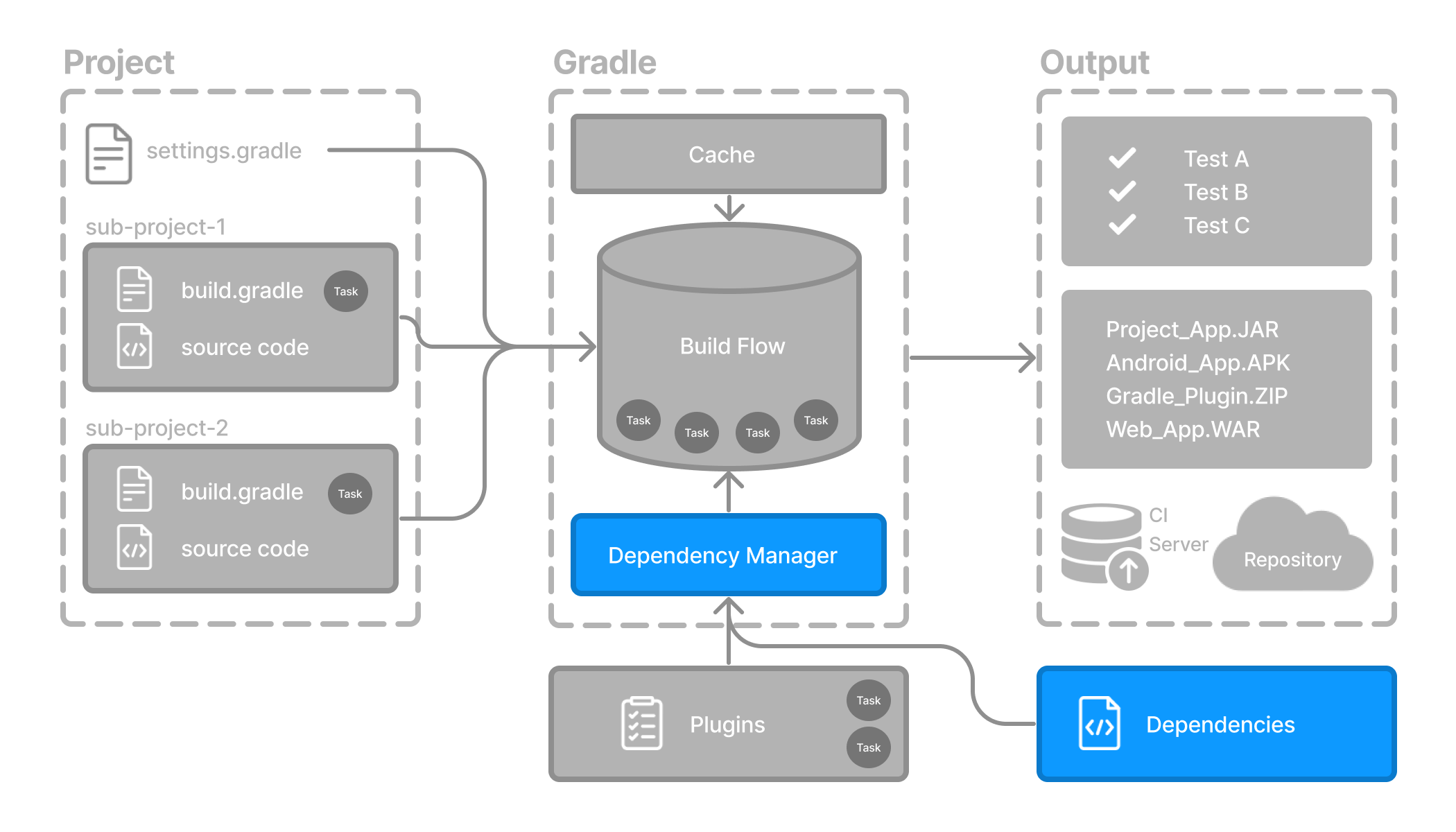
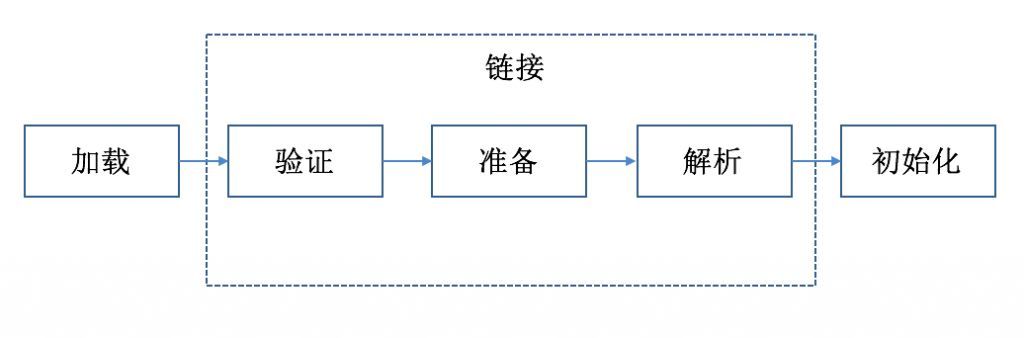
{kind=link}