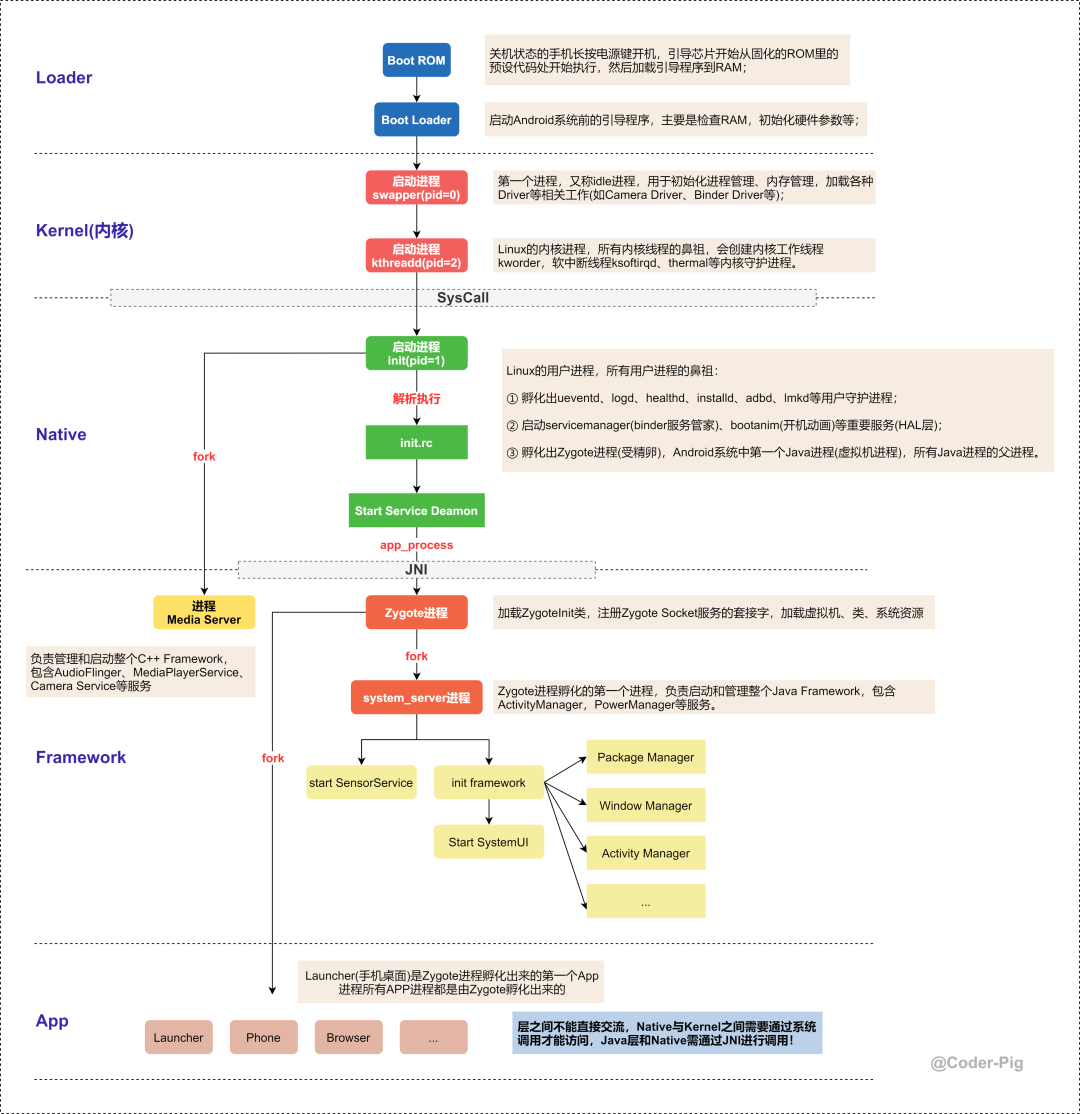
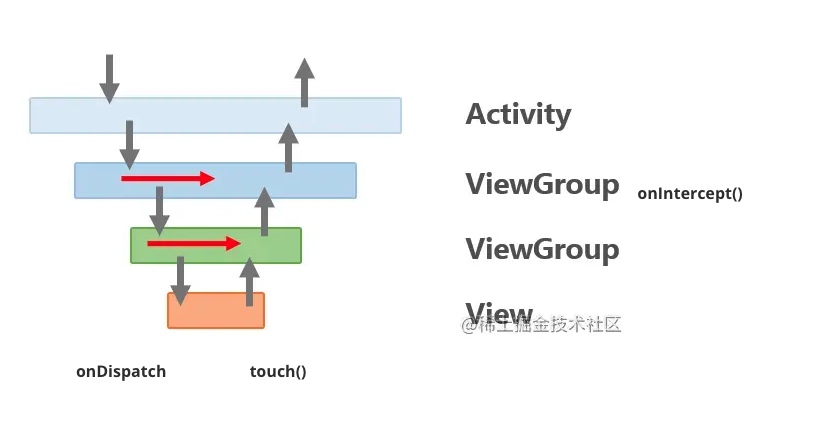
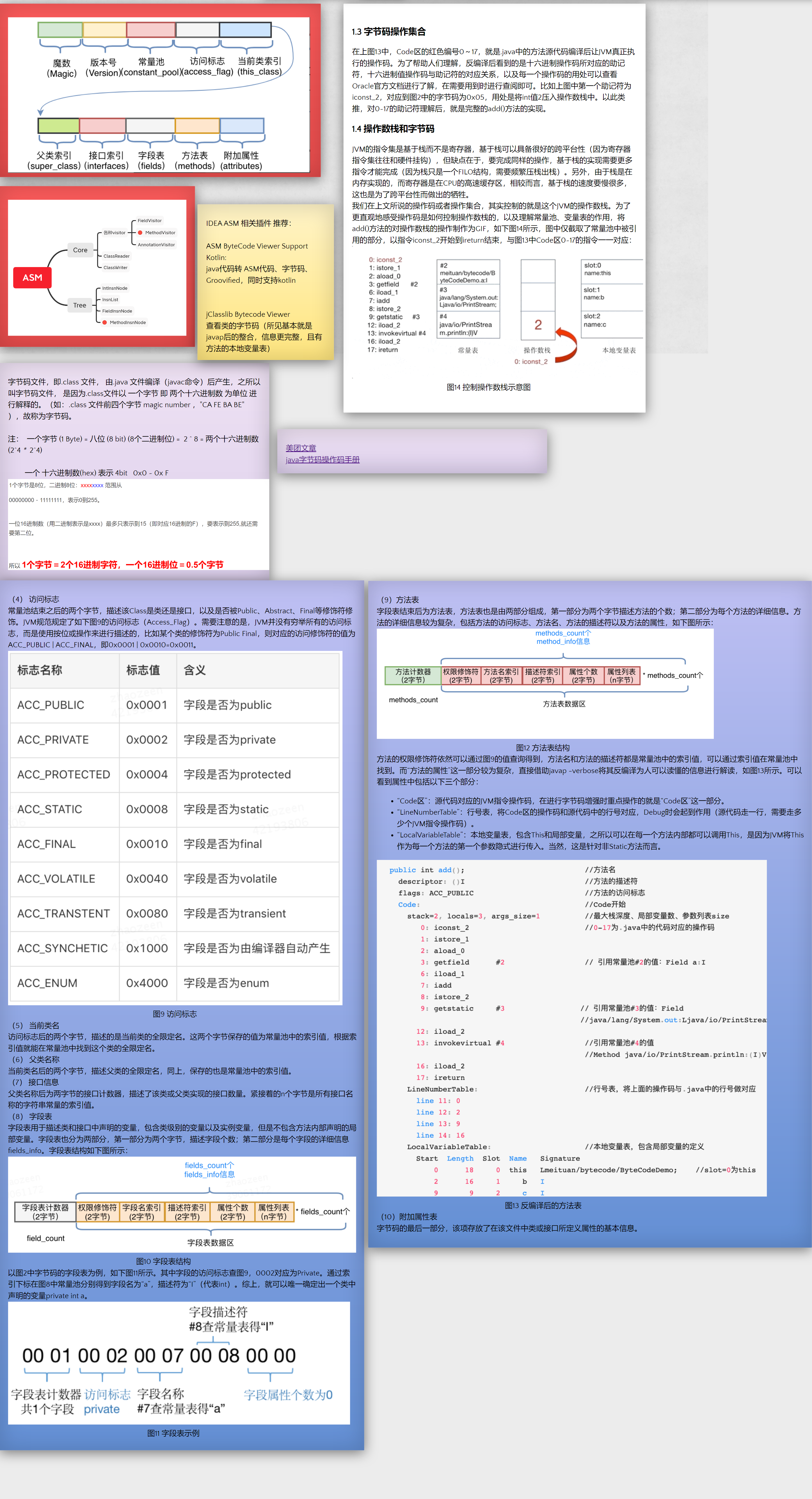
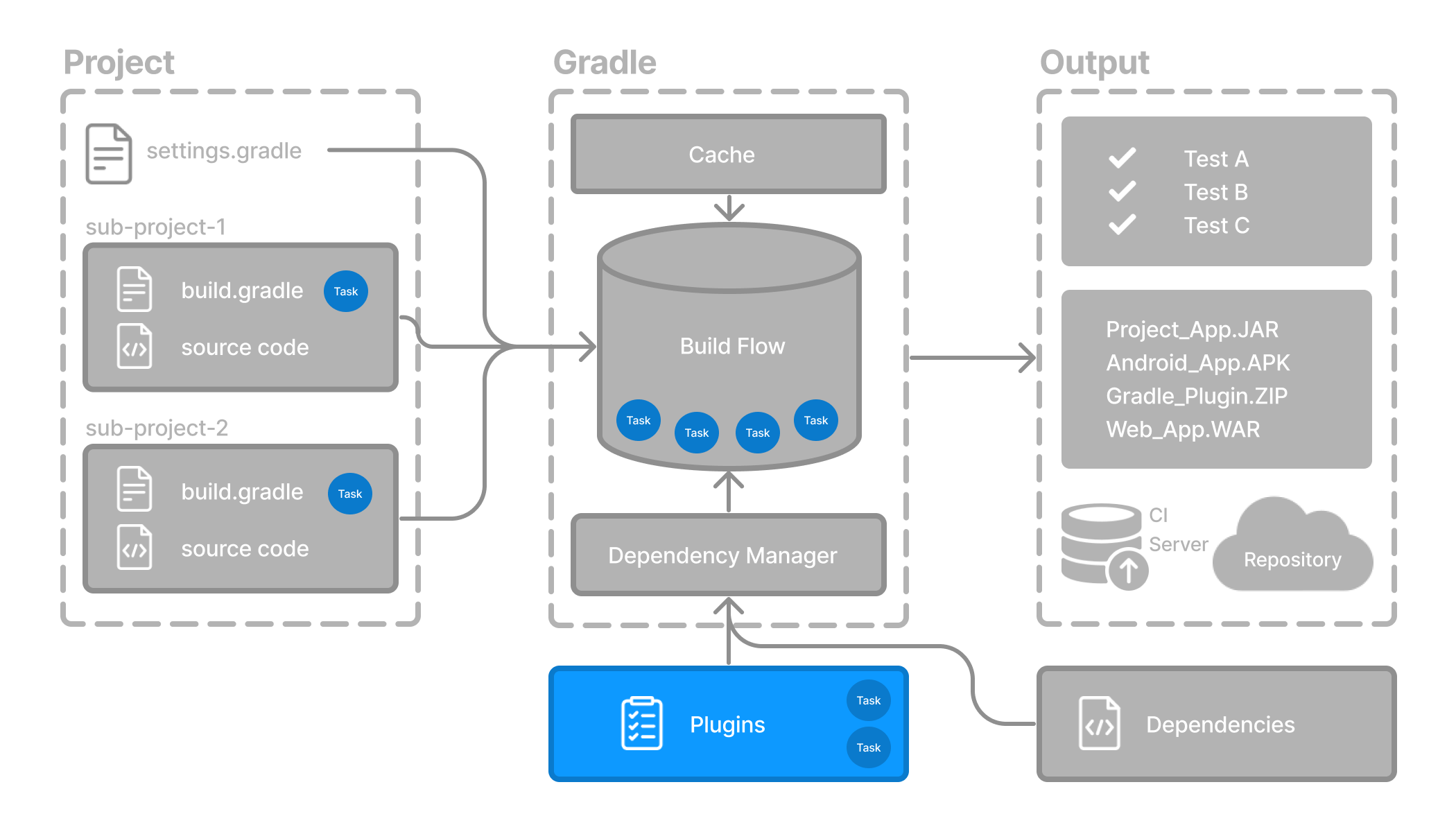
Kotlin
kotlin data class
data class会自动生成以下方法:
equals()
hashCode()
1
2
3
4
5public int hashCode() {
int var10000 = Integer.hashCode(this.age) * 31;
String var10001 = this.name;
return var10000 + (var10001 != null ? var10001.hashCode() : 0);
}toString()
copy()
componentN()
编译器会为数据类生成 组件函数(Component function), 有了这些组件函数, 就可以在 解构声明(destructuring declaration) 中使用数据类:
1
2
3
4val jane = User("Jane", 35)
val (name, age) = jane
println("$name, $age years of age")
// 输出结果为 Jane, 35 years of age属性的get()/set()
val的属性不会有setter
constructor()
只有有参构造函数,没有无参构造函数。fastJson解析会抛该异常,需升级到高版本并引入kotlin-reflect依赖